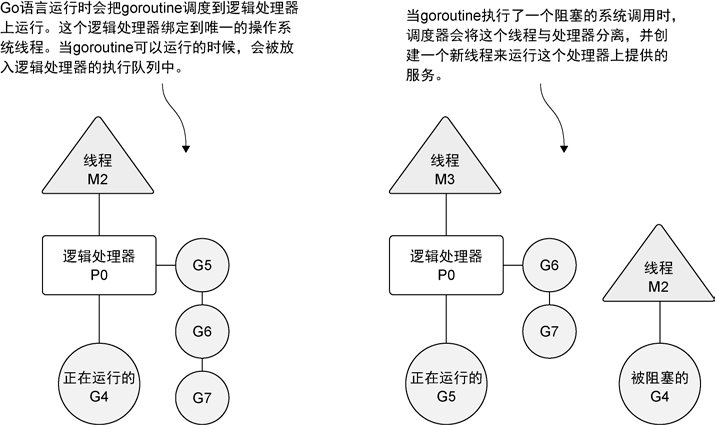
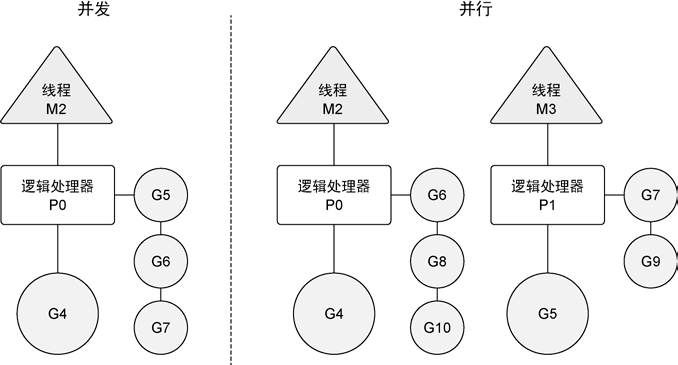
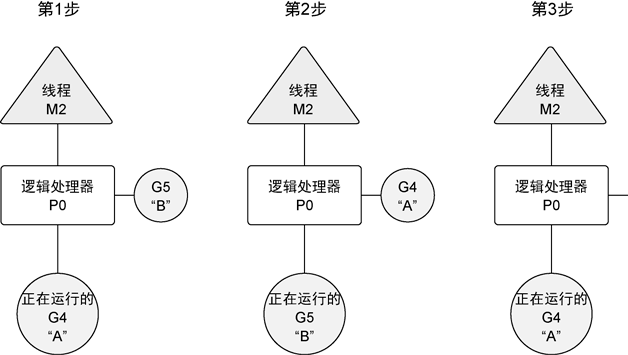
The BackdoorServer provides a REPL inside a running process. As long as the process is monkey-patched, the BackdoorServer can coexist with other elements of the process.
def main(): stop_event = event.Event() servers = [BackdoorServer(('127.0.0.1', 5001), banner="Hello from gevent backdoor!", locals={'foo': "From defined scope!"}), pywsgi.WSGIServer(('127.0.0.1', 5002), start_process, ), ] for server in servers: if not server.started: server.start() stop_event.wait() for server in servers: if server.started: server.stop()
the plane can fly . the typical plane can see the plane . a typical fly can see . who might see ? the large can might see a can . the can can destroy a large can . who might see ? who might fly ? who can fly ? the can might see . the plane can fly a typical fly . who can fly ? the … …
the plane can fly . the typical plane can see the plane . a typical fly can see . who might see ? the large can might see a can . the can can destroy a large can . who might see ? … …
1 the 6 typical 3 can 8 a 9 who 13 destroy 7 see 2 plane 11 ? 10 might 5 . 12 large 4 fly
标注
6 jj 7 wps 2 nn 3 md 1 at 4 vb 5 .
词频统计
1
./../pretrain.pl example0.all lex ngram
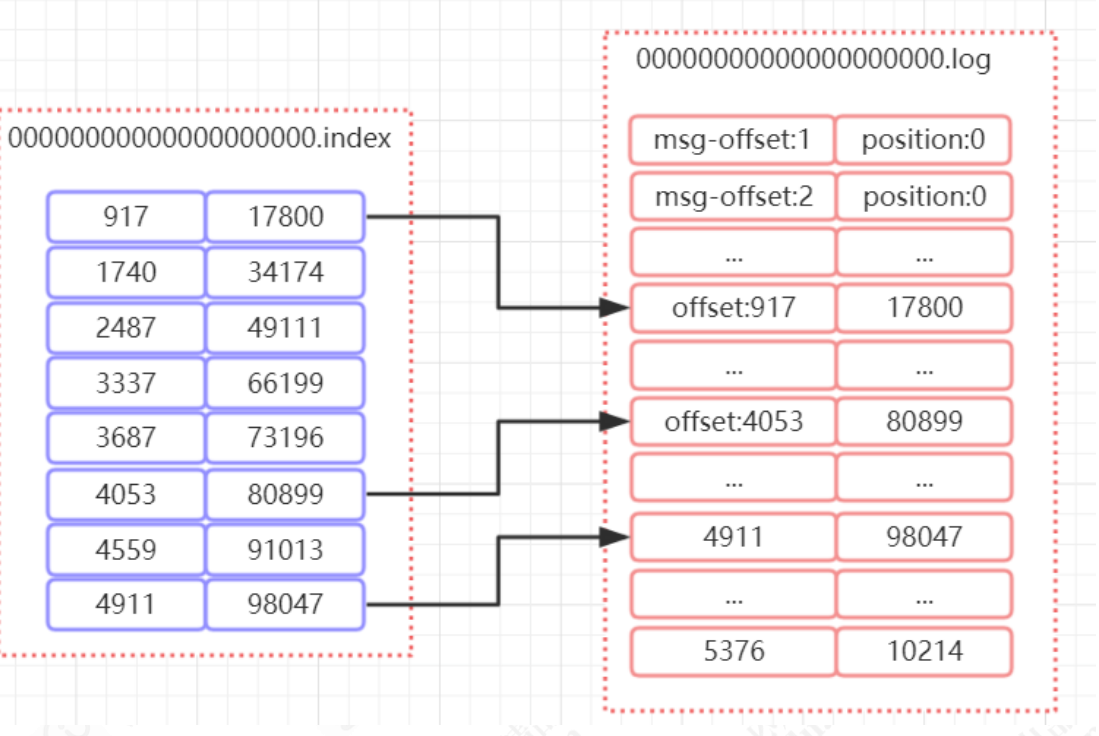
词型及其词性标记的组合在训练集中出现的次数
plane nn 34 a at 58 see vb 45 ? . 57 typical jj 25 large jj 22 destroy vb 9 can md 58 might md 42 can nn 39 fly nn 20 who wps 57 fly vb 46 . . 43 the at 35
一元词性及二元词性在训练集中的出现次数
md 100 wps 57 at 93 . 100 nn 93 vb 100 jj 47 vb . 50 wps md 57 at jj 47 nn . 50 nn md 43 vb at 50 at nn 46 md vb 100 jj nn 47
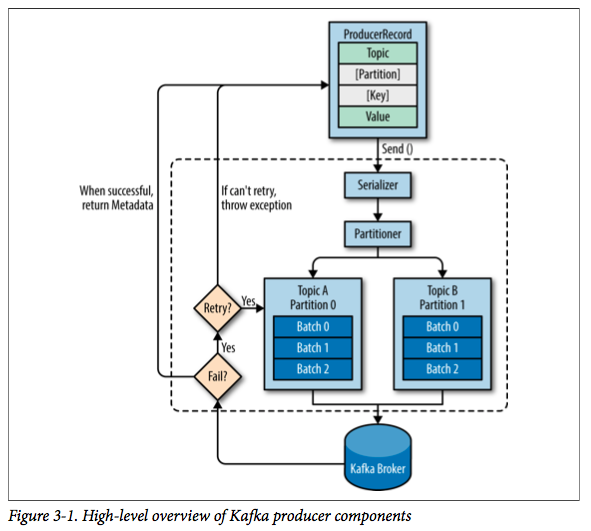
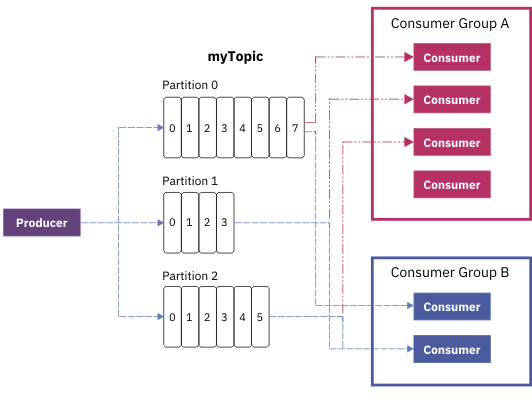
Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 100; i++) producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
// wg is used to wait for the program to finish. var wg sync.WaitGroup
// main is the entry point for all Go programs. funcmain() { // Allocate 1 logical processors for the scheduler to use. runtime.GOMAXPROCS(1)
// Add a count of two, one for each goroutine. wg.Add(2)
// Create two goroutines. fmt.Println("Create Goroutines") go printPrime("A") go printPrime("B")
// Wait for the goroutines to finish. fmt.Println("Waiting To Finish") wg.Wait()
fmt.Println("Terminating Program") }
// printPrime displays prime numbers for the first 5000 numbers. funcprintPrime(prefix string) { // Schedule the call to Done to tell main we are done. defer wg.Done()
next: for outer := 2; outer < 5000; outer++ { for inner := 2; inner < outer; inner++ { if outer%inner == 0 { continue next } } fmt.Printf("%s:%d\n", prefix, outer) } fmt.Println("Completed", prefix) }
var ( // counter is a variable incremented by all goroutines. counter int
// wg is used to wait for the program to finish. wg sync.WaitGroup )
// main is the entry point for all Go programs. funcmain() { // Add a count of two, one for each goroutine. wg.Add(2)
// Create two goroutines. go incCounter(1) go incCounter(2)
// Wait for the goroutines to finish. wg.Wait() fmt.Println("Final Counter:", counter) }
// incCounter increments the package level counter variable. funcincCounter(id int) { // Schedule the call to Done to tell main we are done. defer wg.Done()
for count := 0; count < 2; count++ { // Capture the value of Counter. value := counter
// Yield the thread and be placed back in queue. runtime.Gosched()
// Increment our local value of Counter. value++
// Store the value back into Counter. counter = value } }
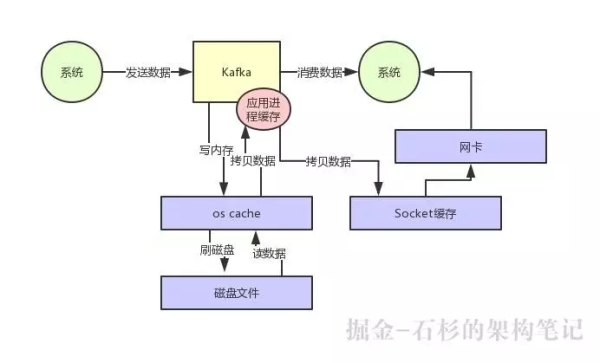
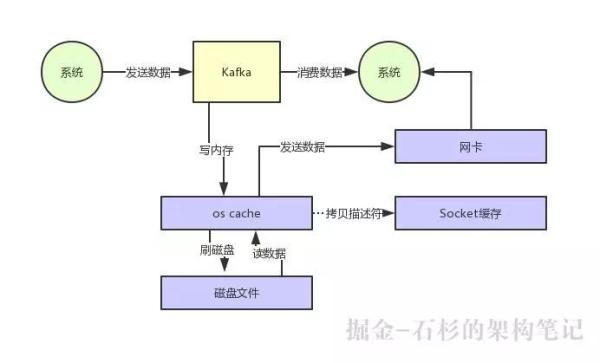
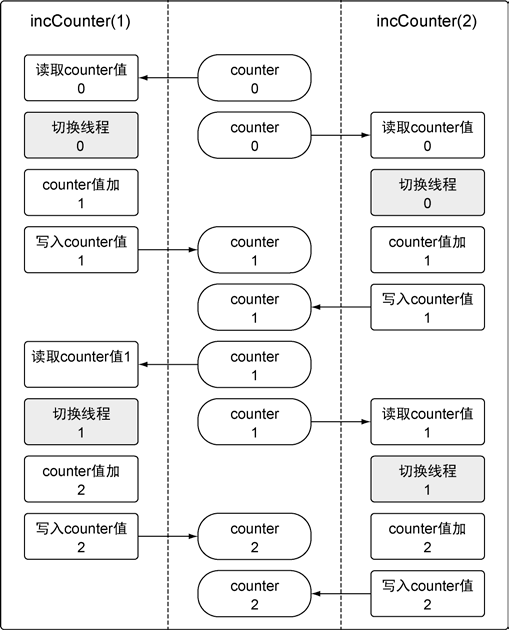
最后counter的值有可能是2,可以用下面这个图描述下过程
可以用go build -race检测代码里的竞争状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
go build -race // 用竞争检测器标志来编译程序 ./example // 运行程序 ================== WARNING: DATA RACE Write by goroutine 5: main.incCounter() /example/main.go:49 +0x96 Previous read by goroutine 6: main.incCounter() /example/main.go:40 +0x66 Goroutine 5 (running) created at: main.main() /example/main.go:25 +0x5c Goroutine 6 (running) created at: main.main() /example/main.go:26 +0x73 ================== Final Counter: 2 Found 1 data race(s)
// This sample program demonstrates how to use a buffered // channel to work on multiple tasks with a predefined number // of goroutines. package main
import ( "fmt" "math/rand" "sync" "time" )
const ( numberGoroutines = 4// Number of goroutines to use. taskLoad = 10// Amount of work to process. )
// wg is used to wait for the program to finish. var wg sync.WaitGroup
// init is called to initialize the package by the // Go runtime prior to any other code being executed. funcinit() { // Seed the random number generator. rand.Seed(time.Now().Unix()) }
// main is the entry point for all Go programs. funcmain() { // Create a buffered channel to manage the task load. tasks := make(chanstring, taskLoad)
// Launch goroutines to handle the work. wg.Add(numberGoroutines) for gr := 1; gr <= numberGoroutines; gr++ { go worker(tasks, gr) }
// Add a bunch of work to get done. for post := 1; post <= taskLoad; post++ { tasks <- fmt.Sprintf("Task : %d", post) }
// Close the channel so the goroutines will quit // when all the work is done. close(tasks)
// Wait for all the work to get done. wg.Wait() }
// worker is launched as a goroutine to process work from // the buffered channel. funcworker(tasks chanstring, worker int) { // Report that we just returned. defer wg.Done()
for { // Wait for work to be assigned. task, ok := <-tasks if !ok { // This means the channel is empty and closed. fmt.Printf("Worker: %d : Shutting Down\n", worker) return }
// Display we are starting the work. fmt.Printf("Worker: %d : Started %s\n", worker, task)
// Randomly wait to simulate work time. sleep := rand.Int63n(100) time.Sleep(time.Duration(sleep) * time.Millisecond)
// Display we finished the work. fmt.Printf("Worker: %d : Completed %s\n", worker, task) } }
// init is called before main. funcinit() { iflen(os.Args) != 2 { fmt.Println("Usage: ./example2 <url>") os.Exit(-1) } }
// main is the entry point for the application. funcmain() { // Get a response from the web server. r, err := http.Get(os.Args[1]) if err != nil { fmt.Println(err) return }
// Copies from the Body to Stdout. io.Copy(os.Stdout, r.Body) if err := r.Body.Close(); err != nil { fmt.Println(err) } }
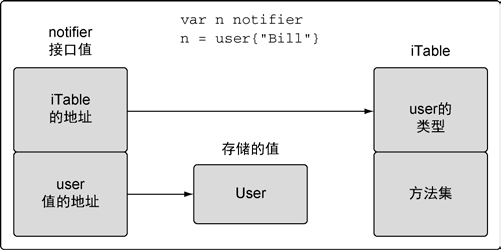
// notifier is an interface that defined notification // type behavior. type notifier interface { notify() }
// user defines a user in the program. type user struct { name string email string }
// notify implements a method with a pointer receiver. func(u *user)notify() { fmt.Printf("Sending user email to %s<%s>\n", u.name, u.email) }
// main is the entry point for the application. funcmain() { // Create a value of type User and send a notification. u := user{"Bill", "bill@email.com"}
sendNotification(u)
// ./listing36.go:32: cannot use u (type user) as type // notifier in argument to sendNotification: // user does not implement notifier // (notify method has pointer receiver) }
// sendNotification accepts values that implement the notifier // interface and sends notifications. funcsendNotification(n notifier) { n.notify() }
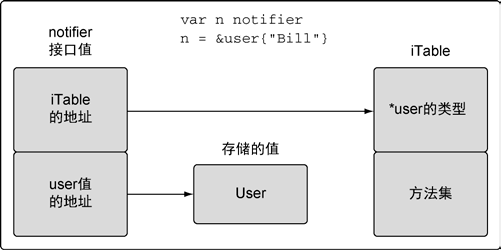
// notifier is an interface that defines notification // type behavior. type notifier interface { notify() }
// user defines a user in the program. type user struct { name string email string }
// notify implements the notifier interface with a pointer receiver. func(u *user)notify() { fmt.Printf("Sending user email to %s<%s>\n", u.name, u.email) }
// admin defines a admin in the program. type admin struct { name string email string }
// notify implements the notifier interface with a pointer receiver. func(a *admin)notify() { fmt.Printf("Sending admin email to %s<%s>\n", a.name, a.email) }
// main is the entry point for the application. funcmain() { // Create a user value and pass it to sendNotification. bill := user{"Bill", "bill@email.com"} sendNotification(&bill)
// Create an admin value and pass it to sendNotification. lisa := admin{"Lisa", "lisa@email.com"} sendNotification(&lisa) }
// sendNotification accepts values that implement the notifier // interface and sends notifications. funcsendNotification(n notifier) { n.notify() }
// user defines a user in the program. type user struct { name string email string }
// notify implements a method that can be called via // a value of type user. func(u *user)notify() { fmt.Printf("Sending user email to %s<%s>\n", u.name, u.email) }
// admin represents an admin user with privileges. type admin struct { user // Embedded Type level string }
// main is the entry point for the application. funcmain() { // Create an admin user. ad := admin{ user: user{ name: "john smith", email: "john@yahoo.com", }, level: "super", }
// We can access the inner type's method directly. ad.user.notify()
// The inner type's method is promoted. ad.notify() }
// A map of registered matchers for searching. // 小写字母标识,标识包内变量,不导出 or 不公开 var matchers = make(map[string]Matcher)
// Run performs the search logic. funcRun(searchTerm string) { // Retrieve the list of feeds to search through. feeds, err := RetrieveFeeds() if err != nil { log.Fatal(err) }
// Create an unbuffered channel to receive match results to display. results := make(chan *Result)
// Setup a wait group so we can process all the feeds. var waitGroup sync.WaitGroup
// Set the number of goroutines we need to wait for while // they process the individual feeds. waitGroup.Add(len(feeds))
// Launch a goroutine for each feed to find the results. for _, feed := range feeds { // Retrieve a matcher for the search. matcher, exists := matchers[feed.Type] if !exists { matcher = matchers["default"] }
// Launch the goroutine to perform the search. gofunc(matcher Matcher, feed *Feed) { Match(matcher, feed, searchTerm, results) waitGroup.Done() }(matcher, feed) }
// Launch a goroutine to monitor when all the work is done. gofunc() { // Wait for everything to be processed. waitGroup.Wait()
// Close the channel to signal to the Display // function that we can exit the program. close(results) }()
// Start displaying results as they are available and // return after the final result is displayed. Display(results) }
// Register is called to register a matcher for use by the program. funcRegister(feedType string, matcher Matcher) { if _, exists := matchers[feedType]; exists { log.Fatalln(feedType, "Matcher already registered") }
// Feed contains information we need to process a feed. type Feed struct { Name string`json:"site"` URI string`json:"link"` Type string`json:"type"` }
// RetrieveFeeds reads and unmarshals the feed data file. funcRetrieveFeeds()([]*Feed, error) { // Open the file. file, err := os.Open(dataFile) if err != nil { returnnil, err }
// Schedule the file to be closed once // the function returns. defer file.Close()
// Decode the file into a slice of pointers // to Feed values. var feeds []*Feed err = json.NewDecoder(file).Decode(&feeds)
// We don't need to check for errors, the caller can do this. return feeds, err }
2.3.3 match.go/default.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
package search
// defaultMatcher implements the default matcher. type defaultMatcher struct{}
// init registers the default matcher with the program. funcinit() { var matcher defaultMatcher Register("default", matcher) }
// Search implements the behavior for the default matcher. func(m defaultMatcher)Search(feed *Feed, searchTerm string)([]*Result, error) { returnnil, nil }
// Result contains the result of a search. type Result struct { Field string Content string }
// Matcher defines the behavior required by types that want // to implement a new search type. type Matcher interface { Search(feed *Feed, searchTerm string) ([]*Result, error) }
// Match is launched as a goroutine for each individual feed to run // searches concurrently. funcMatch(matcher Matcher, feed *Feed, searchTerm string, results chan<- *Result) { // Perform the search against the specified matcher. searchResults, err := matcher.Search(feed, searchTerm) if err != nil { log.Println(err) return }
// Write the results to the channel. for _, result := range searchResults { results <- result } }
// Display writes results to the console window as they // are received by the individual goroutines. funcDisplay(results chan *Result) { // The channel blocks until a result is written to the channel. // Once the channel is closed the for loop terminates. for result := range results { log.Printf("%s:\n%s\n\n", result.Field, result.Content) } }
if __name__ == "__main__": a = decorator(foo) a() a() print(a.__closure__) print(a.__closure__[1].cell_contents) print(a.__closure__[0].cell_contents)
b = decorator(foo) b() b() print(b.__closure__) print(b.__closure__[1].cell_contents) print(b.__closure__[0].cell_contents)
# output # [1] # foo # [1, 1] # foo # (<cell at 0x10eb34198: list object at 0x11a657248>, <cell at 0x10eb344c8: function object at 0x10cee0268>) # <function foo at 0x10cee0268> # [1, 1] # [1] # foo # [1, 1] # foo # (<cell at 0x10eb34a98: list object at 0x112abb188>, <cell at 0x10eb34af8: function object at 0x10cee0268>) # <function foo at 0x10cee0268> # [1, 1]