

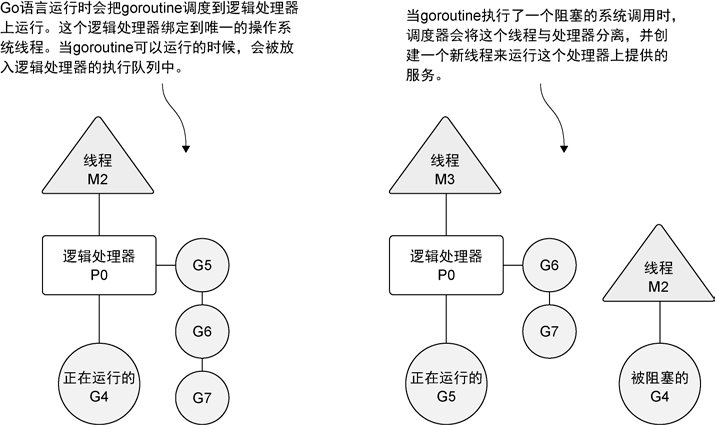
每个goroutine是一个独立的工作单元,这个单元会被调度到可用的逻辑处理器上执行。Go运行时通过调度器管理goroutine,为其分配执行时间。
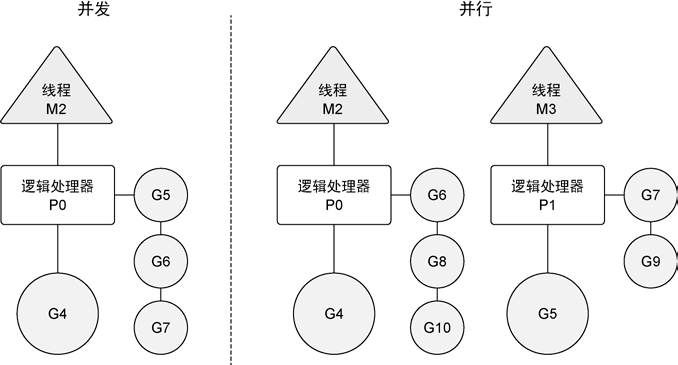
调度器在操作系统之上,将操作系统的线程和语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine。
Go语言通过在goroutine之间传递数据来通信,而不是对数据加锁来实现同步访问。
6.1 并行和并发
并发是让不同的代码片段同时在不同的物理处理器上执行,并发是指同时管理很多事情。
每当创建一个goroutine并准备运行,goroutine被分配到调度器的全局队列中,调度器会给goroutine分配一个逻辑处理器,将goroutine放到逻辑处理器对应的本地队列中。
6.2 goroutine
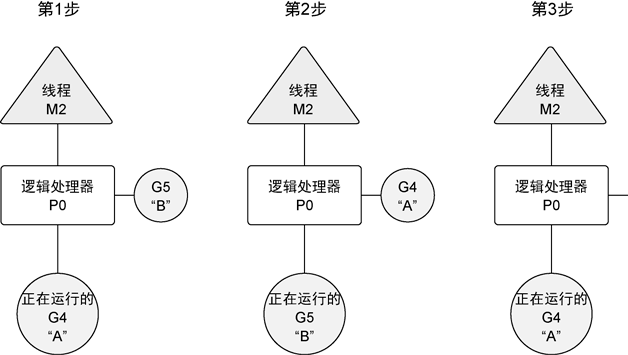
下面这个程序展示了逻辑处理器是如何调度goroutine的,runtime.GOMAXPROCS(1)只允许程序使用一个逻辑处理器。
1 | package main |
可以看到goroutine A和B是交替运行的,因为只有一个逻辑处理器。调度过程可以用下图表示:
6.3 竞争状态
多个goroutine同时对一个共享资源进行读和写,容易进入相互竞争的状态1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49package main
import (
"fmt"
"runtime"
"sync"
)
var (
// counter is a variable incremented by all goroutines.
counter int
// wg is used to wait for the program to finish.
wg sync.WaitGroup
)
// main is the entry point for all Go programs.
func main() {
// Add a count of two, one for each goroutine.
wg.Add(2)
// Create two goroutines.
go incCounter(1)
go incCounter(2)
// Wait for the goroutines to finish.
wg.Wait()
fmt.Println("Final Counter:", counter)
}
// incCounter increments the package level counter variable.
func incCounter(id int) {
// Schedule the call to Done to tell main we are done.
defer wg.Done()
for count := 0; count < 2; count++ {
// Capture the value of Counter.
value := counter
// Yield the thread and be placed back in queue.
runtime.Gosched()
// Increment our local value of Counter.
value++
// Store the value back into Counter.
counter = value
}
}
最后counter的值有可能是2,可以用下面这个图描述下过程
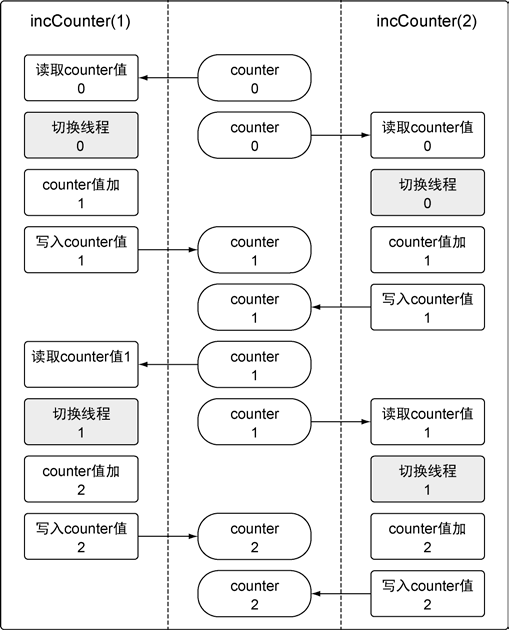
可以用go build -race检测代码里的竞争状态
1 | go build -race // 用竞争检测器标志来编译程序 |
6.4 锁住共享资源
可以使用原子函数和互斥锁解决共享资源的问题
6.4.1 原子函数
原子函数能够以很底层的加锁机制来同步访问整形变量和指针,atomic包提供了一些原子操作,如AddInt64,这个函数会同步整型类型的的加法
LoadInt64和StoreInt64,这两个函数提供了一种安全的读写一个整型值的方式。1
2
3
4var count int64
atomic.AddInt64(&counter, 1)
atomic.LoadInt64(&cunter)
atomic.StoreInt64(&count, 1)
6.4.2 互斥锁
互斥锁用于在代码上创建一个临界区,保证同一时间只有一个goroutine 可以执行这个临界区代码1
2
3
4mutex sync.Mutex
mutex.Lock()
...
mutex.Unlock()
6.5 通道
可以使用make来创建通道1
2
3
4
5
6
7
8
9// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 向通道发送值
buffered <- "Gopher"
// 从通道里接收值
value := <-buffered
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通
道要求发送goroutine 和接收goroutine 同时准备好,才能完成发送和接收操作。如果两个goroutine
没有同时准备好,通道会导致先执行发送或接收操作的goroutine 阻塞等待。这种对通道进行发送
和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
1 | // This sample program demonstrates how to use an unbuffered |
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类
型的通道并不强制要求goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的
条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲
区容纳被发送的值时,发送动作才会阻塞。这导致有缓冲的通道和无缓冲的通道之间的一个很大
的不同:无缓冲的通道保证进行发送和接收的goroutine 会在同一时间进行数据交换;有缓冲的
通道没有这种保证。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77// This sample program demonstrates how to use a buffered
// channel to work on multiple tasks with a predefined number
// of goroutines.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
const (
numberGoroutines = 4 // Number of goroutines to use.
taskLoad = 10 // Amount of work to process.
)
// wg is used to wait for the program to finish.
var wg sync.WaitGroup
// init is called to initialize the package by the
// Go runtime prior to any other code being executed.
func init() {
// Seed the random number generator.
rand.Seed(time.Now().Unix())
}
// main is the entry point for all Go programs.
func main() {
// Create a buffered channel to manage the task load.
tasks := make(chan string, taskLoad)
// Launch goroutines to handle the work.
wg.Add(numberGoroutines)
for gr := 1; gr <= numberGoroutines; gr++ {
go worker(tasks, gr)
}
// Add a bunch of work to get done.
for post := 1; post <= taskLoad; post++ {
tasks <- fmt.Sprintf("Task : %d", post)
}
// Close the channel so the goroutines will quit
// when all the work is done.
close(tasks)
// Wait for all the work to get done.
wg.Wait()
}
// worker is launched as a goroutine to process work from
// the buffered channel.
func worker(tasks chan string, worker int) {
// Report that we just returned.
defer wg.Done()
for {
// Wait for work to be assigned.
task, ok := <-tasks
if !ok {
// This means the channel is empty and closed.
fmt.Printf("Worker: %d : Shutting Down\n", worker)
return
}
// Display we are starting the work.
fmt.Printf("Worker: %d : Started %s\n", worker, task)
// Randomly wait to simulate work time.
sleep := rand.Int63n(100)
time.Sleep(time.Duration(sleep) * time.Millisecond)
// Display we finished the work.
fmt.Printf("Worker: %d : Completed %s\n", worker, task)
}
}
上面代码需要注意的是close(tasks),关闭通道后,goroutine依旧可以从通道接收数据,但是不能再向通道里发送数据。
6.6 小结
并发是指goroutine运行的时候是相互独立的
使用关键字go创建goroutine来运行函数
goroutine在逻辑处理器上执行,逻辑处理器具有独立的系统线程和运行队列
竞争状态是指两个或者多个goroutine试图访问同一个资源
原子函数和互斥锁提供了一种防止出现竞争状态的办法
通道提供了一种在两个goroutine之间共享数据的简单方法
无缓冲的通道保证同时交换数据,而有缓冲的通道不做这种保证
